Web Scraping
Web scraping, web harvesting, or web data extraction
-
is data scraping used for extracting data from websites. The web scraping software may directly access the World Wide Web using the Hypertext Transfer Protocol or a web browser. While web scraping can be done manually by a software user, the term typically refers to automated processes implemented using a bot or web crawler. It is a form of copying in which specific data is gathered and copied from the web, typically into a central local database or spreadsheet, for later retrieval or analysis.
-
Web scraping a web page involves fetching it and extracting from it. Fetching is the downloading of a page (which a browser does when a user views a page). Therefore, web crawling is a main component of web scraping, to fetch pages for later processing. Once fetched, then extraction can take place. The content of a page may be parsed, searched, reformatted, its data copied into a spreadsheet or loaded into a database. Web scrapers typically take something out of a page, to make use of it for another purpose somewhere else. An example would be to find and copy names and telephone numbers, or companies and their URLs, or e-mail addresses to a list (contact scraping).
-
Web scraping is used for contact scraping, and as a component of applications used for web indexing, web mining and data mining, online price change monitoring and price comparison, product review scraping (to watch the competition), gathering real estate listings, weather data monitoring, website change detection, research, tracking online presence and reputation, web mashup, and web data integration.
-
Web pages are built using text-based mark-up languages (HTML and XHTML), and frequently contain a wealth of useful data in text form. However, most web pages are designed for human end-users and not for ease of automated use. As a result, specialized tools and software have been developed to facilitate the scraping of web pages.
-
Newer forms of web scraping involve monitoring data feeds from web servers. For example, JSON is commonly used as a transport storage mechanism between the client and the web server.
-
There are methods that some websites use to prevent web scraping, such as detecting and disallowing bots from crawling (viewing) their pages. In response, there are web scraping systems that rely on using techniques in DOM parsing, computer vision and natural language processing to simulate human browsing to enable gathering web page content for offline parsing.
Respect Robots.txt
- Web spiders should ideally follow the robot.txt file for a website while scraping. It has specific rules for good behavior, such as how frequently you can scrape, which pages allow scraping, and which ones you can’t. Some websites allow Google to scrape their websites, by not allowing any other websites to scrape. This goes against the open nature of the Internet and may not seem fair, but the owners of the website are within their rights to resort to such behavior.
You can find the robot.txt file on websites. It is usually the root directory of a website – http://example.com/robots.txt.
If it contains lines like the ones shown below, it means the site doesn’t like and does not want to be scraped.
User-agent: *
Disallow:/
Make the crawling slower, do not slam the server, treat websites nicely
-
Web scraping bots fetch data very fast, but it is easy for a site to detect your scraper, as humans cannot browse that fast. The faster you crawl, the worse it is for everyone. If a website gets too many requests than it can handle it might become unresponsive.
-
Make your spider look real, by mimicking human actions. Put some random programmatic sleep calls in between requests, add some delays after crawling a small number of pages and choose the lowest number of concurrent requests possible. Ideally, put a delay of 10-20 seconds between clicks and not put much load on the website, treating the website nice.
-
Use auto throttling mechanisms which will automatically throttle the crawling speed based on the load on both the spider and the website that you are crawling. Adjust the spider to an optimum crawling speed after a few trial runs. Do this periodically because the environment does change over time.
Do not follow the same crawling pattern
- Humans generally will not perform repetitive tasks as they browse through a site with random actions. Web scraping bots tend to have the same crawling pattern because they are programmed that way unless specified. Sites that have intelligent anti-crawling mechanisms can easily detect spiders by finding patterns in their actions and can lead to web scraping getting blocked.
Incorporate some random clicks on the page, mouse movements and random actions that will make a spider look like a human.
Make requests through Proxies and rotate them as needed to
- When scraping, your IP address can be seen. A site will know what you are doing and if you are collecting data. They could take data such as – user patterns or experience if they are first-time users.
Multiple requests coming from the same IP will lead you to get blocked, which is why we need to use multiple addresses. When we send requests from a proxy machine, the target website will not know where the original IP is from, making the detection harder.
There are several methods that can change your outgoing IP.
- TOR
- VPNs
- Free Proxies
- Shared Proxies – the least expensive proxies shared by many users. The chances of getting blocked are high.
- Private Proxies – usually used only by you, and lower chances of getting blocked if you keep the frequency low.
-
Data Center Proxies, if you need a large number of IP Addresses and faster proxies, larger pools of IPs. They are cheaper than residential proxies and could be detected easily.
- Residential Proxies, if you are making a huge number of requests to websites that block to actively. These are very expensive (and could be slower, as they are real devices). Try everything else before getting a residential proxy.
Rotate User Agents and corresponding HTTP Request Headers between requests
- A user agent is a tool that tells the server which web browser is being used. If the user agent is not set, websites won’t let you view content. Every request made from a web browser contains a user-agent header and using the same user-agent consistently leads to the detection of a bot. You can get your User-Agent by typing ‘what is my user agent’ in Google’s search bar. The only way to make your User-Agent appear more real and bypass detection is to fake the user agent. Most web scrapers do not have a User Agent by default, and you need to add that yourself.
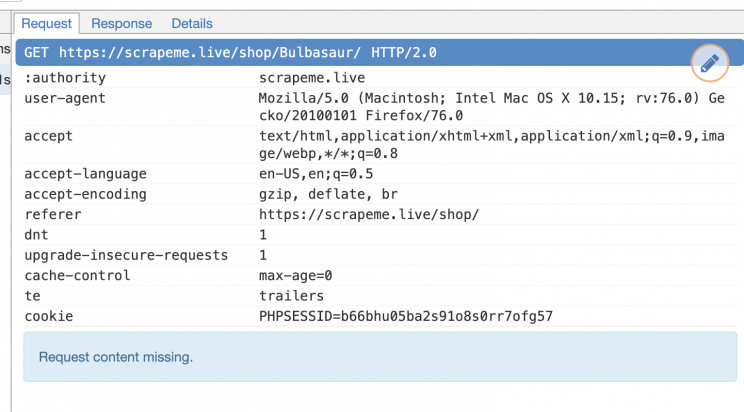
The most basic ones are:
- User-Agent
- Accept
- Accept-Language
- Referer
- DNT
- Updgrade-Insecure-Requests
- Cache-Control